Contrastive Learning of Sentence Representations
A novel approach which applies contrastive learning to learn universal sentence representations on top of pre-trained language models.
The work on this project has published in ICON 2021. Take a look at “Contrastive Learning of Sentence Rrepresentations” for more details.
Objective
Learning sentence representations which capture rich semantic meanings has been crucial for many NLP tasks. Pre-trained language models such as BERT have achieved great success in NLP, but sentence embeddings extracted directly from these models do not perform well without fine-tuning. We aim to learn universal sentence representations which better encode semantic.
Proposed Model
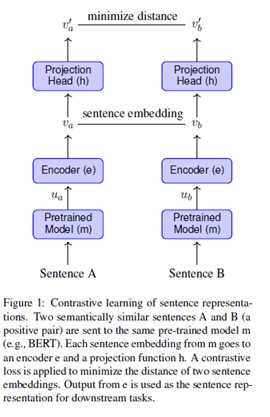
We propose Contrastive Learning of Sentence Representations (CLSR), a novel approach which applies contrastive learning to learn universal sentence representations on top of pre-trained language models. CLSR utilizes semantic similarity of two sentences to construct positive instances for contrastive learning. Semantic information that has been captured by the pre-trained models is kept by getting sentence embeddings from these models with proper pooling strategy. An encoder followed by a linear projection takes these embeddings as inputs and is trained under a contrastive objective. To evaluate the performance of CLSR, we ran experiments on a range of pre-trained language models and their variants on a series of Semantic Contextual Similarity tasks. Results show that CLSR gains significant performance improvements over existing SOTA language models.